
这个算法一看就是比较复杂的 要是直接去对字符串进行操作 一定十分麻烦 我们自然就想到使用动态规划的思路 去把大问题分解为一个个子问题 通过前面的状态来决定后面的状态 进而一步步推出最终结果
接下来我们再说明一下动态规划的基本操作步骤
1. 定义状态(State Definition)
- 确定状态变量:首先,确定问题的最优解可以通过哪些状态变量来表示。这些状态变量通常表示子问题的解。
- 状态的含义:状态通常是一个数组或表格,用来存储子问题的解。例如,在背包问题中,
dp[i][w]表示前i个物品中,重量为w时的最大价值。
2. 状态转移方程(State Transition or Recurrence Relation)
- 确定状态之间的关系:根据问题的结构,找出如何从已知的子问题解构建更大问题的解。通常,这是通过递推公式(也叫递归公式)来描述的。
- 例如,在背包问题中,
dp[i][w]的值可以通过以下两种方式获得:- 不选第
i个物品:dp[i][w] = dp[i-1][w] - 选择第
i个物品:dp[i][w] = dp[i-1][w-weight[i]] + value[i](如果容量w足够) - 然后,选择这两者中的最大值:
dp[i][w] = max(dp[i-1][w], dp[i-1][w-weight[i]] + value[i])
- 不选第
3. 初始化(Initialization)
- 初始化边界条件:根据问题的要求,初始化动态规划表格的边界。边界条件通常对应最简单的子问题,通常是状态变量的初始值。
- 例如,背包问题的初始化边界为:
dp[0][w] = 0:0个物品时,任何容量下的最大价值为 0。dp[i][0] = 0:任何物品集合,容量为 0 时的最大价值为 0。
4. 填充 DP 表格(Fill DP Table)
- 按顺序填表:通常,动态规划表格是从小到大逐步填充的。根据状态转移方程,填充每个子问题的解,并将其保存到表格中。填充时要确保每个状态的值是基于已经计算出的子问题解。
5. 获取答案(Extract Result)
例如,在背包问题中,dp[n][W] 代表使用前 n 个物品,背包容量为 W 时的最大价值。
从表格中读取最终结果:最终结果通常保存在动态规划表格的一个位置,可能是表格的右下角或者某个特定的单元格,具体取决于问题的定义。
本题解决
简单介绍了动态规划的基本步骤 现在我们来解决这个算法问题
题目让我们计算操作的最少次数使得DNA1变为DNA2 我们可以从第一个字符开始计算
1.定义状态
创建一个二维数组 dp,其中 dp[i][j] 表示将 DNA1 的前 i 个字符转换为 DNA2 的前 j 个字符所需的最小操作次数
2.初始化
dp[i][0] = i:将dna1的前i个字符转换为空字符串,需要i次删除操作。dp[0][j] = j:将空字符串转换成dna2的前j个字符,需要j次插入操作。
确定了动态规划的边界 以这个边界为基础进行后续的递推计算
3.状态转移方程
(1) 如果 dna1[i-1] == dna2[j-1]:
- 这意味着当前的字符是相同的,不需要进行任何操作,直接继承上一步的最优解。
- 也就是说,
dp[i][j] = dp[i-1][j-1]。 - 例子:假设
dna1 = "AGCT"和dna2 = "AGCT",比较到A和A时,它们相同,就不需要任何操作,所以dp[i][j]保持为dp[i-1][j-1]的值。
(2) 如果 dna1[i-1] != dna2[j-1]:
- 这意味着当前字符不同,我们需要选择一个操作(删除、插入或替换)来使两个字符串匹配。然后我们选择这三种操作中的最小操作次数。
dp[i][j] 的计算,我们有三种选择:
- 删除(
dna1[i-1]):如果我们选择删除dna1[i-1],则dp[i][j] = dp[i-1][j] + 1,表示我们将dna1的前i-1个字符转换为dna2的前j个字符后,再进行一次删除操作(即删除dna1[i-1]) - 插入(
dna2[j-1]):如果我们选择在dna1[i-1]后插入dna2[j-1],则dp[i][j] = dp[i][j-1] + 1,表示我们将dna1的前i个字符转换为dna2的前j-1个字符后,再进行一次插入操作(即插入dna2[j-1]) - 替换(
dna1[i-1]和dna2[j-1]):如果我们选择将dna1[i-1]替换成dna2[j-1],则dp[i][j] = dp[i-1][j-1] + 1,表示我们将dna1的前i-1个字符转换为dna2的前j-1个字符后,再进行一次替换操作(即将dna1[i-1]替换为dna2[j-1])
总结递推公式:
- 如果
dna1[i-1] == dna2[j-1],则dp[i][j] = dp[i-1][j-1]。 - 如果
dna1[i-1] != dna2[j-1],则dp[i][j] = 1 + min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]),其中:dp[i-1][j]表示删除操作的结果,dp[i][j-1]表示插入操作的结果,dp[i-1][j-1]表示替换操作的结果。
4.最终结果:
- 最后,
dp[m][n]就是将dna1转换为dna2所需的最小操作次数。
我们以字符串”kitten”(dna1)和字符串”sitting”(dna2)为例 对这个状态方程进行说明
我详细地画出了dp状态表 并举例分析了每种操作的意义( 应该足够详细了吧 )
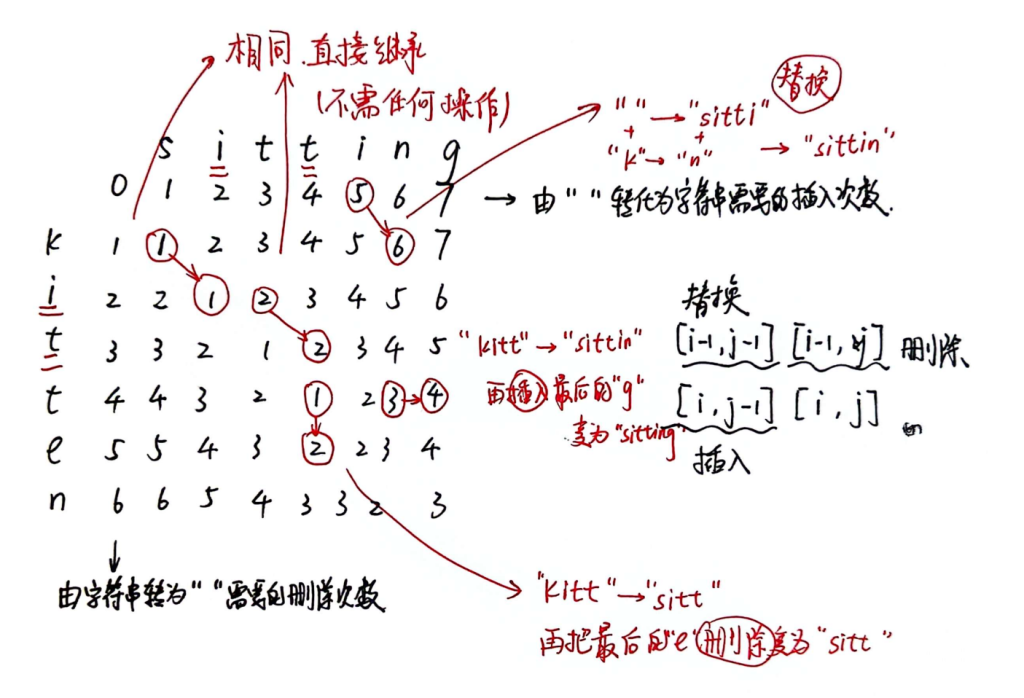
很明显 最少操作次数就是3啦~
这就是一个动态规划算法的应用 原实现函数的代码贴在下面
int solution(std::string dna1, std::string dna2) {
int m = dna1.size();
int n = dna2.size();
// 创建一个二维数组 dp,大小为 (m+1) x (n+1)
std::vector<std::vector<int>> dp(m + 1, std::vector<int>(n + 1, 0));
// 初始化 dp 数组的第一行和第一列
for (int i = 0; i <= m; ++i) {
dp[i][0] = i; // 将 dna1 的前 i 个字符转换成空字符串,需要 i 次删除操作
}
for (int j = 0; j <= n; ++j) {
dp[0][j] = j; // 将空字符串转换成 dna2 的前 j 个字符,需要 j 次插入操作
}
// 填充 dp 数组
for (int i = 1; i <= m; ++i) {
for (int j = 1; j <= n; ++j) {
if (dna1[i – 1] == dna2[j – 1]) {
dp[i][j] = dp[i – 1][j – 1]; // 不需要任何编辑操作
} else {
dp[i][j] = 1 + std::min({dp[i – 1][j], // 删除
dp[i][j – 1], // 插入
dp[i – 1][j – 1] // 替换
});
}
}
}
// 返回最终结果
return dp[m][n];
}